Crear relaciones en base de datos
Imprimir
Este video te puede ayudar a construir las relaciones en tu base de datos.

Imprimir
Este video te puede ayudar a construir las relaciones en tu base de datos.
Imprimir
A la hora de crear un campo en una tabla, hay que especificar de qué tipo son los datos que se van a almacenar en ese campo.
Los diferentes tipos de datos de Access son:
Texto: cuando en el campo vamos a introducir texto, tanto caracteres como dígitos. Tiene una longitud por defecto de 50 caracteres, siendo su longitud máxima de 255 caracteres.
Memo: se utiliza para textos extensos como comentarios o explicaciones. Tiene una longitud fija de 65.535 caracteres.
Numérico: para datos numéricos utilizados en cálculos matemáticos.
Fecha/Hora: para la introducción de fechas y horas desde el año 100 al año 9999.
Moneda: para valores de moneda y datos numéricos utilizados en cálculos matemáticos en los que estén implicados datos que contengan entre uno y cuatro decimales. La precisión es de hasta 15 dígitos a la izquierda del separador decimal y hasta 4 dígitos a la derecha del mismo.
Autonumérico: número secuencial (incrementado de uno a uno) único, o número aleatorio que Microsoft Access asigna cada vez que se agrega un nuevo registro a una tabla. Los campos Autonumérico no se pueden actualizar.
Sí/No: valores Sí y No, y campos que contengan uno de entre dos valores (Sí/No, Verdadero/Falso o Activado/desactivado).
Objeto OLE: Objeto (como por ejemplo una hoja de cálculo de Microsoft Excel, un documento de Microsoft Word, gráficos, sonidos u otros datos binarios).
Hipervínculo: Texto o combinación de texto y números almacenada como texto y utilizada como dirección de hipervínculo. Una dirección de hipervínculo puede tener hasta tres partes:
Texto: el texto que aparece en el campo o control.
Dirección: ruta de acceso de un archivo o página.
Subdirección: posición dentro del archivo o página.
Sugerencia: el texto que aparece como información sobre herramientas.
Existe otra posibilidad que es la Asistente para búsquedas que crea un campo que permite elegir un valor de otra tabla o de una lista de valores mediante un cuadro de lista o un cuadro combinado. Al hacer clic en esta opción se inicia el Asistente para búsquedas y al salir del Asistente, Microsoft Access establece el tipo de datos basándose en los valores seleccionados en él.
Imprimir
aquí esta otro video para que inicies con la creacion de algunas tablas.
Imprimir
Si el maestro no se expreso en el aula, o disidiste no ponerle atencion aquí está un link que te puede ayudar.
Imprimir
La programación por capas es un estilo de programación en el que el objetivo primordial es la separación de la lógica de negocios de la lógica de diseño; un ejemplo básico de esto consiste en separar la capa de datos de la capa de presentación al usuario.
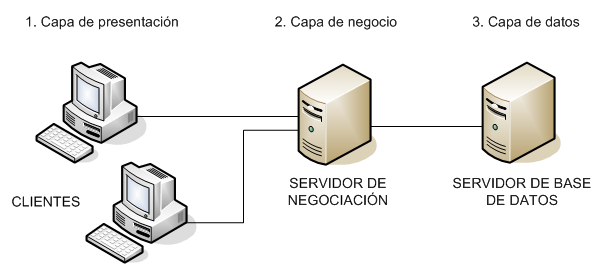
Imprimir
Hay tres características importantes inherentes a los sistemas de bases de datos: la separación entre los programas de aplicación y los datos, el manejo de múltiples vistas por parte de los usuarios y el uso de un catálogo para almacenar el esquema de la base de datos. En 1975, el comité ANSI-SPARC (American National Standard Institute - Standards Planning and Requirements Committee) propuso una arquitectura de tres niveles para los sistemas de bases de datos, que resulta muy útil a la hora de conseguir estas tres características.
El objetivo de la arquitectura de tres niveles es el de separar los programas de aplicación de la base de datos física. En esta arquitectura, el esquema de una base de datos se define en tres niveles de abstracción distintos:

Concepto | Wikipedia | Otro | Esquema |
|---|---|---|---|
Modelo de base de datos | Técnicas son usadas para modelar la estructura de datos. | Es una colección de herramientas conceptuales para describir los datos, las relaciones que existen entre ellos, semántica asociada a los datos y restricciones de consistencia. | - - - - - - - - - - - - - |
Modelo de red | Organiza datos que usan dos fundamental construcciones, registros llamados y conjuntos. Los registros contienen campos. Los conjuntos se definen de uno a varios relaciones entre registros: un propietario, muchos miembros. Un registro puede ser un propietario en cualquier número de conjuntos, y un miembro en cualquier número de conjuntos. Es una variación sobre el modelo jerárquico, al grado que es construido sobre el concepto de múltiples ramas emanando de uno o varios nodos, mientras el modelo se diferencia del modelo jerárquico en esto las ramas pueden estar unidas a múltiples nodos. | En este modelo las entidades se representan como nodos y sus relaciones son las líneas que los unen. En esta estructura cualquier componente puede relacionarse con cualquier otro. A diferencia del modelo jerárquico, en este modelo, un hijo puede tener varios padres. Los conceptos básicos en el modelo en red son:
| 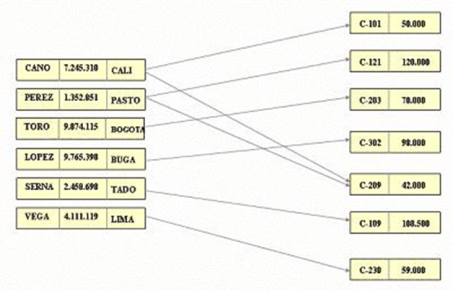 |
Modelo jerárquico | En un modelo jerárquico, los datos son organizados en una estructura parecida a un árbol, implicando un eslabón solo ascendente en cada registro para describir anidar, y un campo de clase para guardar los registros en un orden particular en cada lista de mismo-nivel. Esta estructura permite un 1:N en una relación entre dos tipos de datos. Esta estructura es muy eficiente para describir muchas relaciones en el verdadero real; recetas, índice, ordenamiento de párrafos/versos, alguno anidó y clasificó la información. En la relación Padre-hijo: El hijo sólo puede tener un padre pero un padre puede tener múltiples hijos. Los padres e hijos son atados juntos por eslabones "indicadores" llamados. Un padre tendrá una lista de indicadores de cada uno de sus hijos. | Este modelo utiliza árboles para la representación lógica de los datos. Este árbol esta compuesto de unos elementos llamados nodos. El nivel más alto del árbol se denomina raíz. Cada nodo representa un registro con sus correspondientes campos. La representación gráfica de este modelo se realiza mediante la creación de un árbol invertido, los diferentes niveles quedan unidos mediante relaciones. | 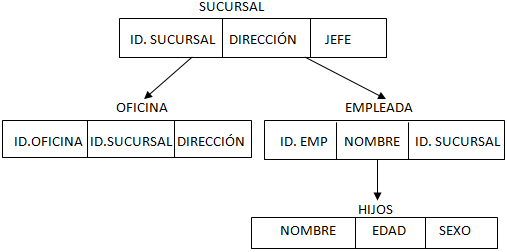 |
Modelo Entidad-Relación | El Modelo Entidad-Relación, también conocido como DER (diagramas entidad-relación) es una herramienta de modelado para bases de datos, mediante el cual se pretende 'visualizar' los objetos que pertenecen a la Base de Datos como entidades las cuales tienen unos atributos y se vinculan mediante relaciones. Es una representación conceptual de la información. Mediante una serie de procedimientos se puede pasar del modelo E-R a otros, como por ejemplo el modelo relacional. El modelado entidad-relación es una técnica para el modelado de datos utilizando diagramas entidad relación. No es la única técnica pero sí la más utilizada. Brevemente consiste en los siguientes pasos:
| Denominado por sus siglas como: E-R; Este modelo representa a la realidad a través de entidades, que son objetos que existen y que se distinguen de otros por sus características. Las entidades pueden ser de dos tipos:
| |
Modelo relacional | El modelo relacional fue presentado como un modo de hacer sistemas de gestión de datos más independientes de cualquier uso particular. Esto es un modelo matemático definido en términos de predicado lógico y la teoría de juego. Tres términos clave son usados extensivamente en el Modelo Relacional: relaciones, atributos, y dominios. Una relación, figurativamente hablando, es una tabla con columnas y filas. El atributo, es un descriptor de la relación, figurativamente hablando, sería el encabezado de cada una de las columnas de la tabla. El dominio de un atributo es el conjunto de valores legales que puede tomar el atributo. La estructura de datos básica del modelo relacional es la tabla, donde la información sobre una entidad particular (decir, un empleado) es representado en columnas y filas (también llamado tuplas). Así, "la relación" en "la base de datos relacionada" se refiere a varias tablas en la base de datos; una relación es un juego de tuplas. Las columnas enumeran varios atributos de la entidad (el nombre del empleado, la dirección o el número de teléfono, por ejemplo), y una fila es un caso real de la entidad (un empleado específico) que es representado por la relación. Por consiguiente, cada tupla de la tabla de empleado representa varios atributos de un empleado solo. Todas las relaciones (y tablas) en una base de datos relacionada tienen que adherirse a algunas reglas básicas de licenciarse como relaciones. Primero, el ordenamiento de columnas es inmaterial en una tabla. Segundo, no puede haber tuplas idénticas o filas en una tabla. Y tercero, cada tuple contendrá un valor solo para cada uno de sus atributos. Una base de datos relacional contiene múltiples tablas, cada similar al que en el modelo de base de datos "plano". Una de las fuerzas del modelo relacional es que, en principio, cualquier valor que ocurre en dos registros diferentes (perteneciendo a la misma tabla o a tablas diferentes), implica una relación entre aquellos dos registros. Una llave que puede ser usada únicamente identificar una fila en una tabla una llave primaria. Las llaves comúnmente son usadas unir o combinar datos de dos o más tablas. Por ejemplo, una tabla de Empleado puede contener una columna la Ubicación llamada que contiene un valor que empareja la llave de una tabla de Ubicación. Las llaves son también críticas en la creación de índices, que facilitan la recuperación rápida de datos de mesas grandes. Cualquier columna puede ser una llave, o múltiples columnas pueden ser agrupadas juntos en una llave compuesta. No es necesario definir todas las llaves por adelantado; una columna puede ser usada como una llave incluso si al principio no fue querido para ser el que. Una llave externa que tiene un significado en el mundo real (como el nombre de una persona, ISBN de un libro, o el número de serie de un coche) es una llave "natural". Si ninguna llave natural es conveniente (pensar en mucha gente elnombre José), un a llave arbitraria o sustituta puede ser asignada (como dando a empleados numeros ID). En la práctica, la mayor parte de bases de datos han generado ambas y llaves naturales, porque las llaves generadas pueden ser usadas internamente crear eslabones entre las filas que no pueden romperse, mientras llaves naturales pueden ser usadas, menos de fuentes fidedignas, para búsquedas y para la integración con otras bases de datos. (Por ejemplo, los registros en dos bases de datos por separado desarrolladas podrían ser correspondidos por el número de la Seguridad Social, excepto cuando los números de la Seguridad Social son incorrectos, la omisión(la acción de echar de menos), o se han cambiado). | Este modelo es el más utilizado actualmente ya que utiliza tablas bidimensionales para la representación lógica de los datos y sus relaciones. Algunas de sus principales caracteristicas son:
El elemento principal de este modelo es la relación que se representa mediante una tabla. |  |